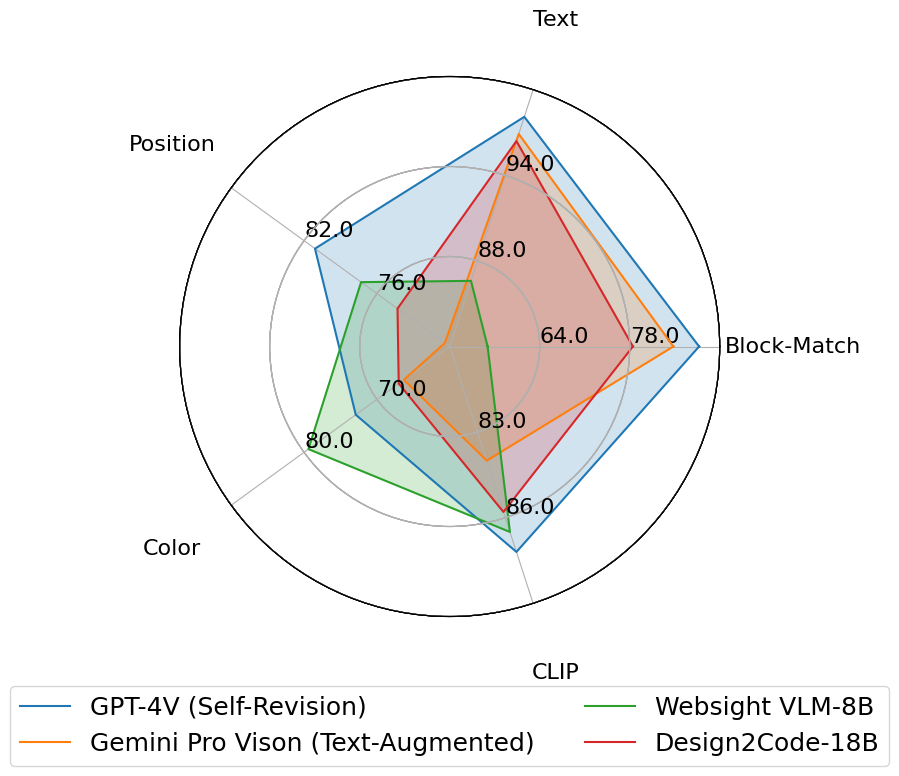
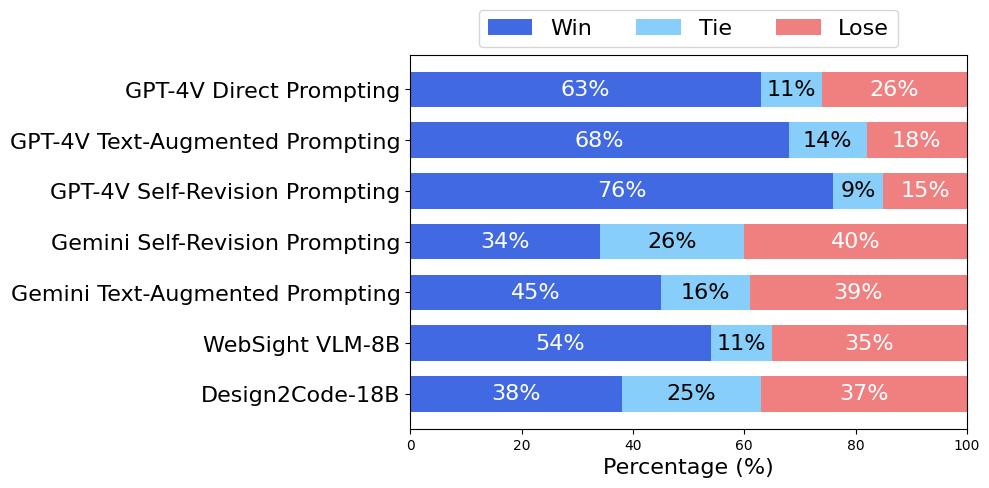
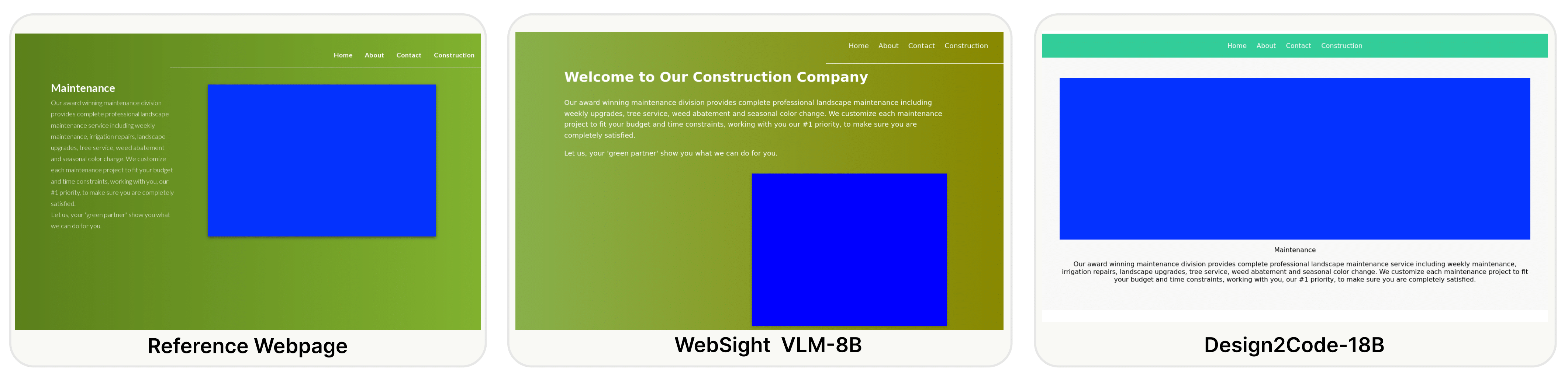
Generative AI has made rapid advancements in recent years, achieving unprecedented capabilities in multimodal understanding and code generation. This enabled a brand new paradigm of front-end development, where multimodal LLMs can potentially convert visual designs into code implementations directly, thus automating the front-end engineering pipeline. In this work, we provide the first systematic study on this visual design to code implementation task (dubbed as Design2Code). We manually curate a benchmark of 484 real-world webpages as test cases and develop a set of automatic evaluation metrics to assess how well current multimodal LLMs can generate the code implementations that directly render into the given reference webpages, given the screenshots as input. We develop a suit of multimodal prompting methods and show their effectiveness on GPT-4V and Gemini Vision Pro. We also finetune an open-source Design2Code-18B model that successfully matches the performance of Gemini Pro Vision. Both human evaluation and automatic metrics show that GPT-4V is the clear winner on this task, where annotators think GPT-4V generated webpages can replace the original reference webpages in 49% cases in terms of visual appearance and content; and perhaps surprisingly, in 64% cases GPT-4V generated webpages are considered better than even the original reference webpages. Our fine-grained break-down metrics indicate that open-source models mostly lag in recalling visual elements from the input webpages and in generating correct layout designs, while aspects like text content and coloring can be drastically improved with proper finetuning.