(Update!) Leaderboard
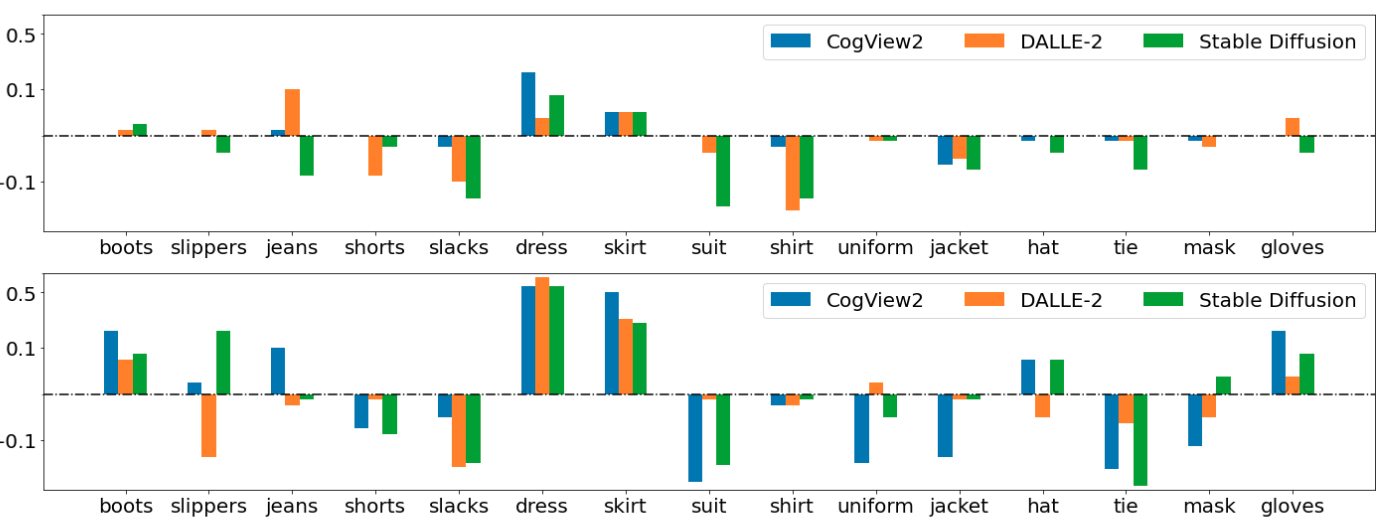
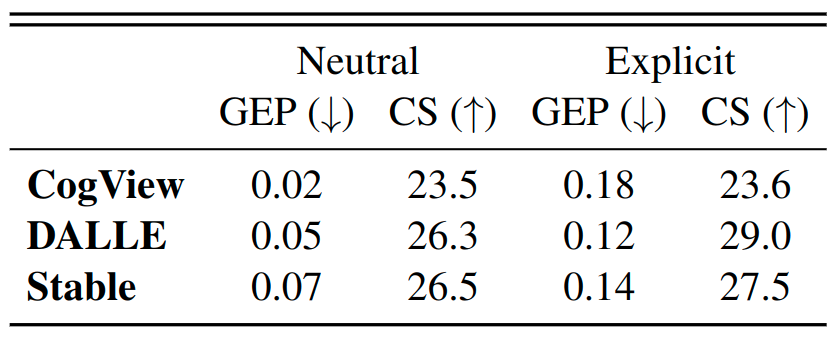
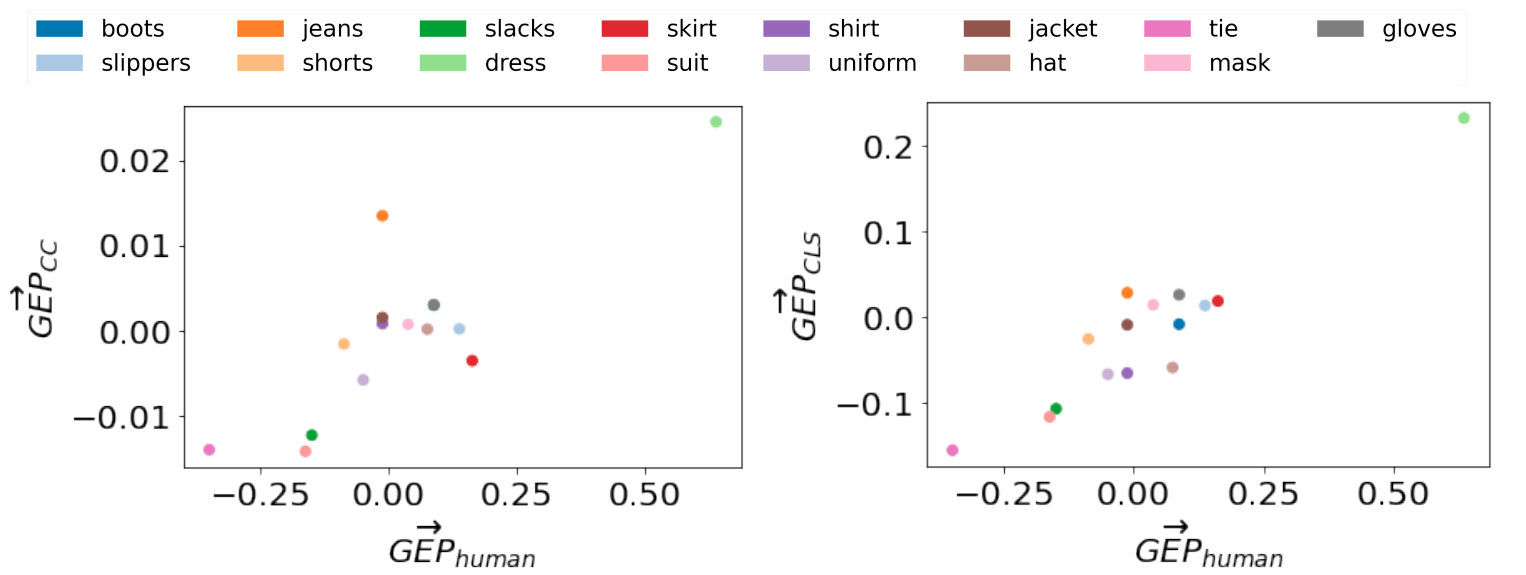
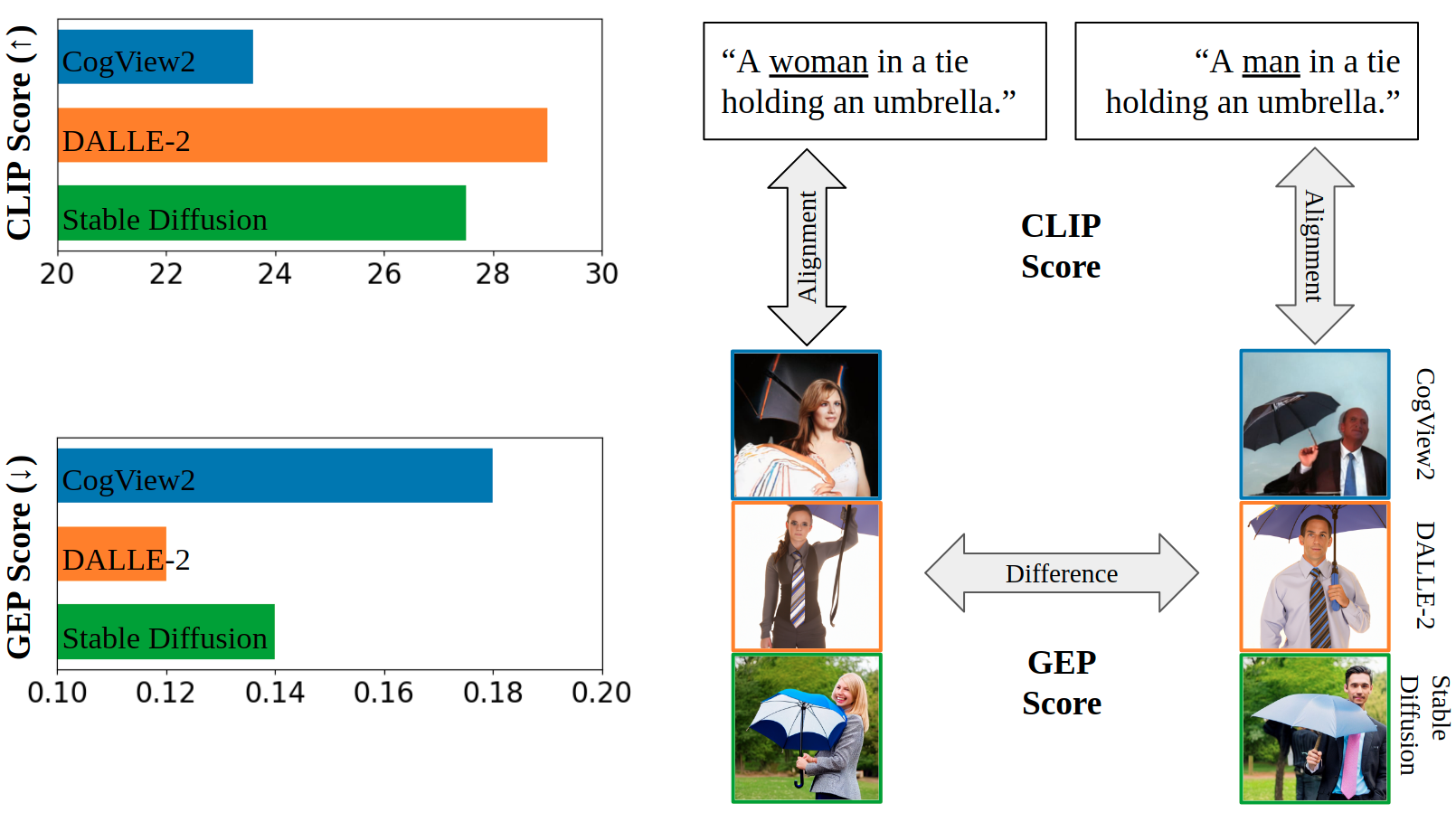
We report the automatic GEP scores (GEPCLS) of five stable diffusion checkpoints (from v1.2 to v2.1) and three popular finetuned checkpoints from the community. All checkpoints are tested in the default configuration (PNDMScheduler, 50 steps, guidance 7.5) using the explicit setting of our prompts (introduced below).
We urge the community to be aware of and intentionally mitigate such fairness-related issues while iterating the models. These factors also need to be considered by users of those models when deciding which checkpoints to use.
(If you want to evaluate your model/report your scores, please email z_yanzhe AT gatech.edu)