Sketches are a natural and accessible medium for UI designers to conceptualize early-stage ideas. However, existing research on UI/UX automation often requires high-fidelity inputs like Figma designs or detailed screenshots, limiting accessibility and impeding efficient design iteration. To bridge this gap, we introduce Sketch2Code, a benchmark that evaluates state-of-the-art Vision Language Models (VLMs) on automating the conversion of rudimentary sketches into webpage prototypes. Beyond end-to-end benchmarking, Sketch2Code supports interactive agent evaluation that mimics real-world design workflows, where a VLM-based agent iteratively refines its generations by communicating with a simulated user, either passively receiving feedback instructions or proactively asking clarification questions. We comprehensively analyze ten commercial and open-source models, showing that Sketch2Code is challenging for existing VLMs; even the most capable models struggle to accurately interpret sketches and formulate effective questions that lead to steady improvement. Nevertheless, a user study with UI/UX experts reveals a significant preference for proactive question-asking over passive feedback reception, highlighting the need to develop more effective paradigms for multi-turn conversational agents.
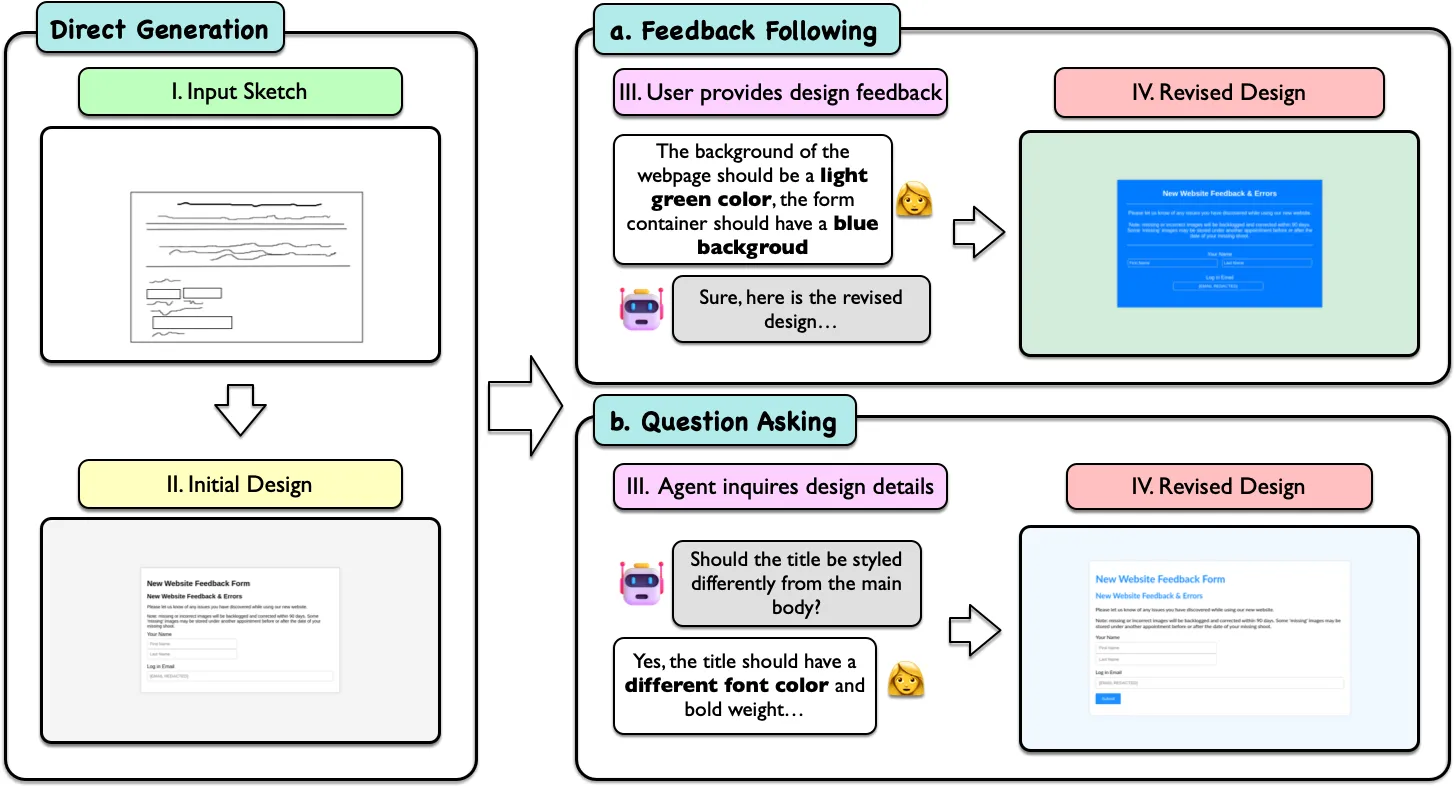
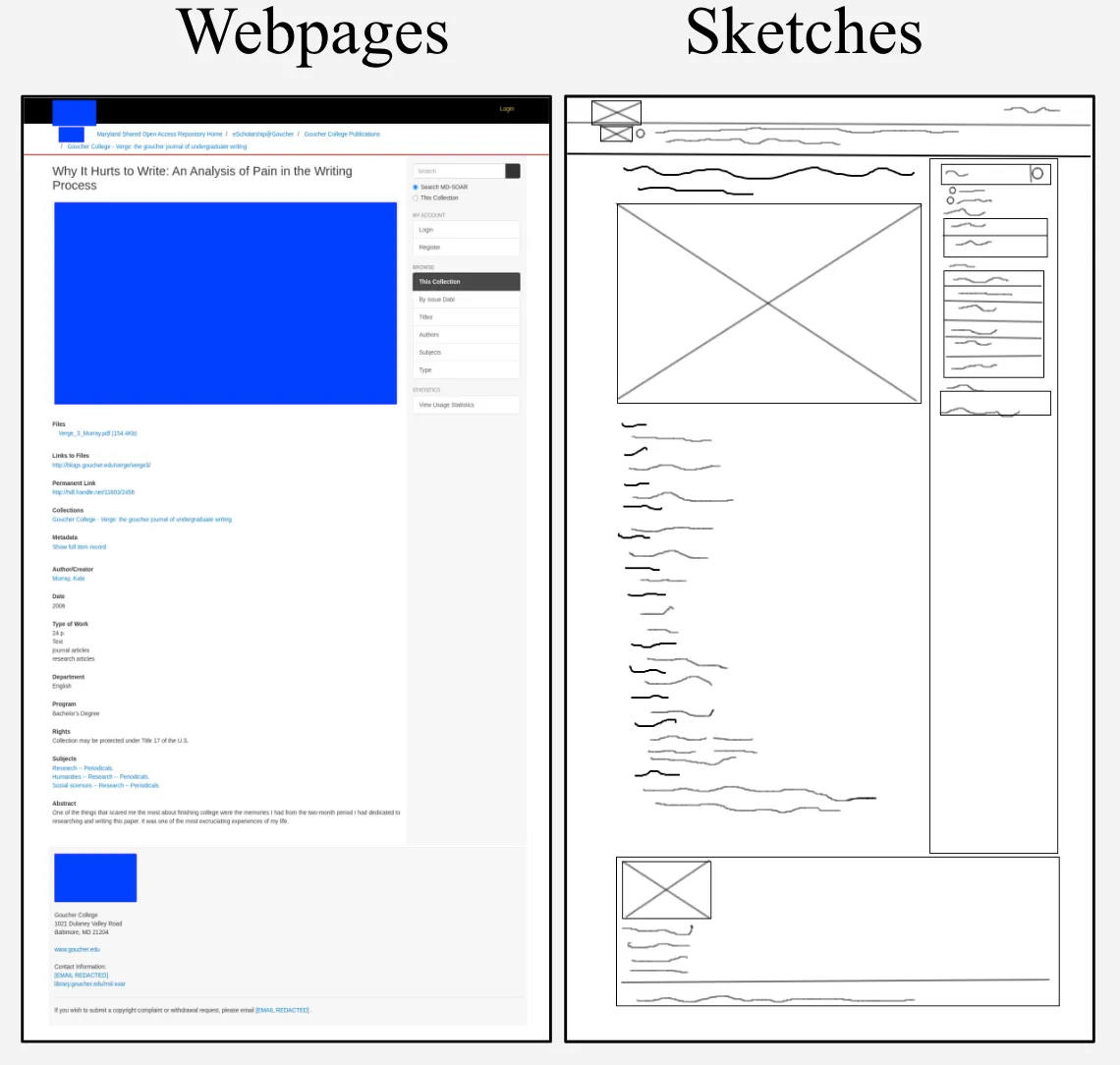
Sketch2Code consists of 731 human-drawn sketches paired with 484 real-world webpages with varying levels of precision and drawing styles. To mirror realistic design workflows and study how well VLMs can interact with humans, our framework further introduces two multi-turn evaluation scenarios between a sketch2code agent and a human/simulated user: (1) the sketch2code agent follows feedback from the user (feedback following) and (2) the sketch2code agent proactively asks the user questions for design details and clarification (question asking). To this end, our framework assesses not only the ability of models to generate initial implementations based on abstract inputs but also their capacity to adapt and evolve these implementations in response to user feedback.
We evaluated 8 commercial models (GPT-4o, GPT-4o mini, Gemini 1.5 Pro, Gemini 1.5 Flash, Claude 3.5 Sonnet, Claude 3 Opus/Sonnet/Haiku), and 2 open-source models (Llava-1.6-8b and InternVL2-8b). Claude 3.5 Sonnet leads the performance in single-turn generations, achieving the best results in both automated metrics and human satisfaction rates.
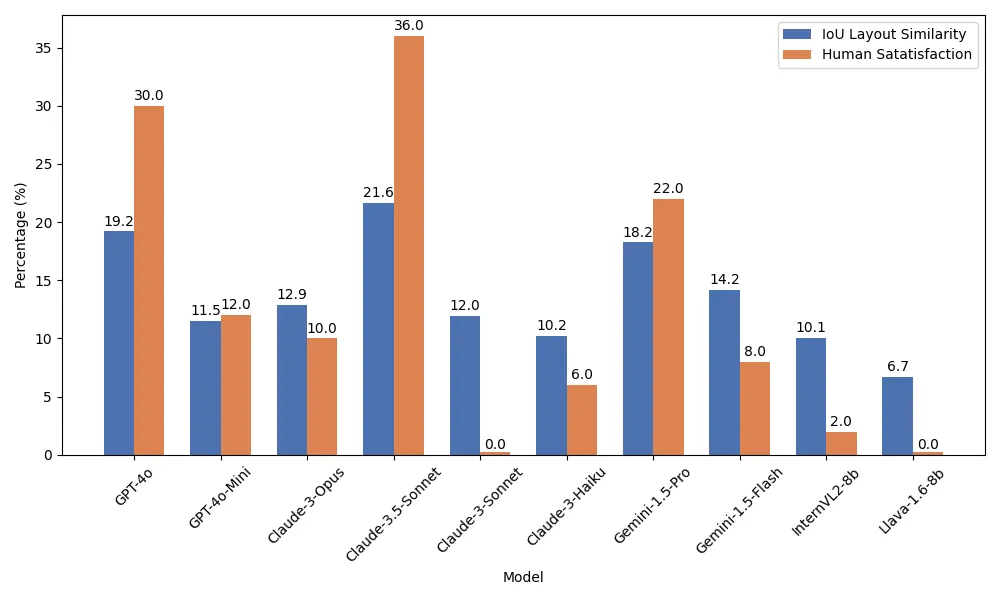

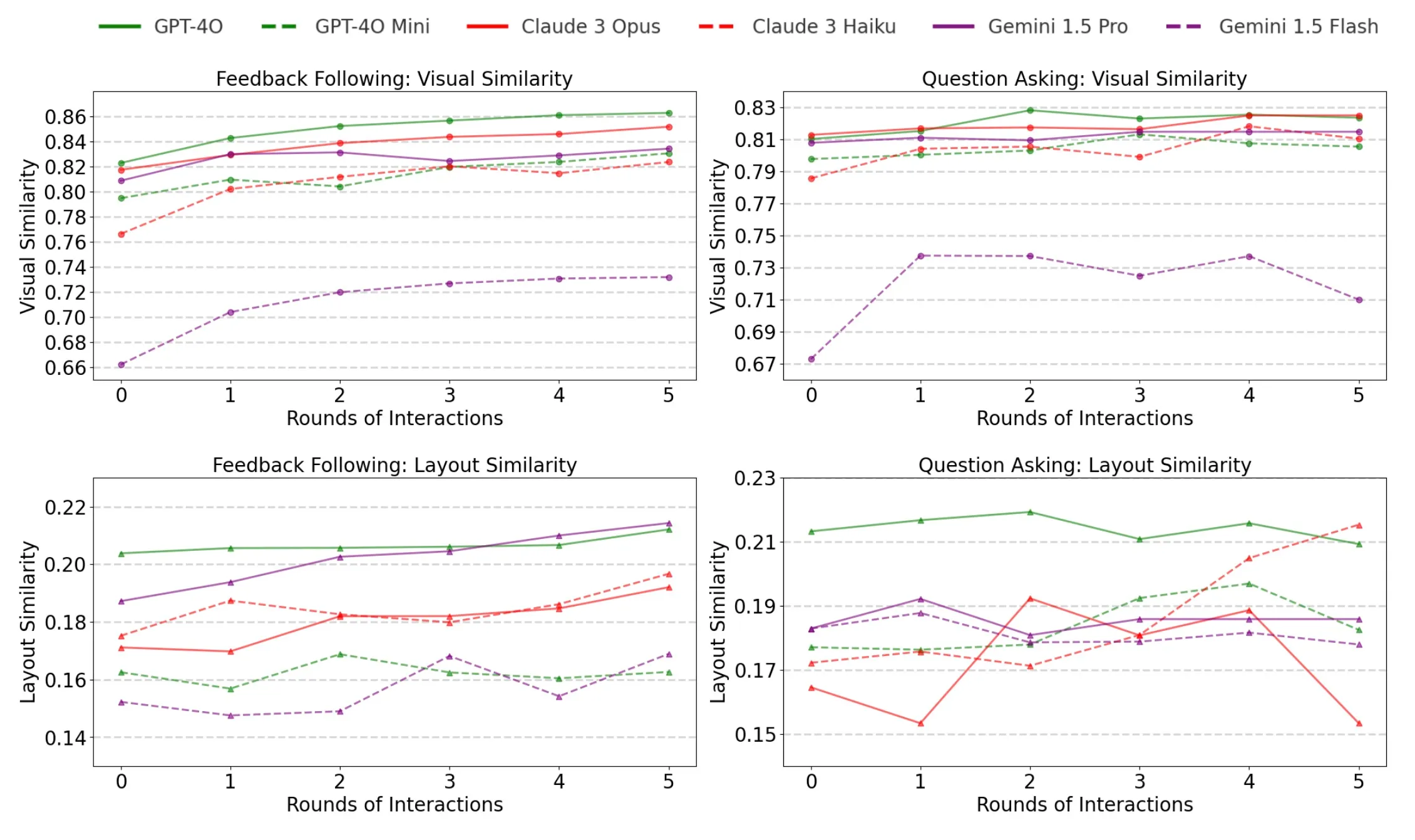
We find that all models displayed noticeable improvements in feedback following. The best commercial models achieves improvements of up to 7.1% in visual similarity and 2.7% in IoU-based layout similarity within five rounds of interaction. Quesion asking, however, appears to be a more challenging task as all models struggled to pose effective questions about the sketches and showed very few improvements with statistical significance.



@misc{li2024sketch2codeevaluatingvisionlanguagemodels,
title={Sketch2Code: Evaluating Vision-Language Models for Interactive Web Design Prototyping},
author={Ryan Li and Yanzhe Zhang and Diyi Yang},
year={2024},
eprint={2410.16232},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.16232},
}